4 minute read.A Lustrum over the weekend
The ancient Romans performed a purification rite (“lustration”) after taking a census every five years. The term “lustrum” designated not only the animal sacrifice (“suovetaurilia”) but was also applied to the period of time itself. At Crossref, we’re not exactly in the business of sacrificial rituals. But over the weekend I thought it would be fun to dive into the metadata and look at very high level changes during this period of time.
Crossref provides the latest cumulative stats online. We share news about the work we do along the way in the Crossref blog, including periodic summaries such as the Executive Director’s 2017 end-of-year highlights and the annual review. But what follows is a brief and very informal survey of the population of inhabitants in the Crossref metadata-land for the current lustrum.
Works published
The first thing a census typically asks is population size. We know there are new records arriving each month with 95.7mil to date. And they do so at variable rates. But when the data is visualized, a rough yearly pattern emerges into view. (Data were collected on Mar 25, 2018; results are partial for this month.)
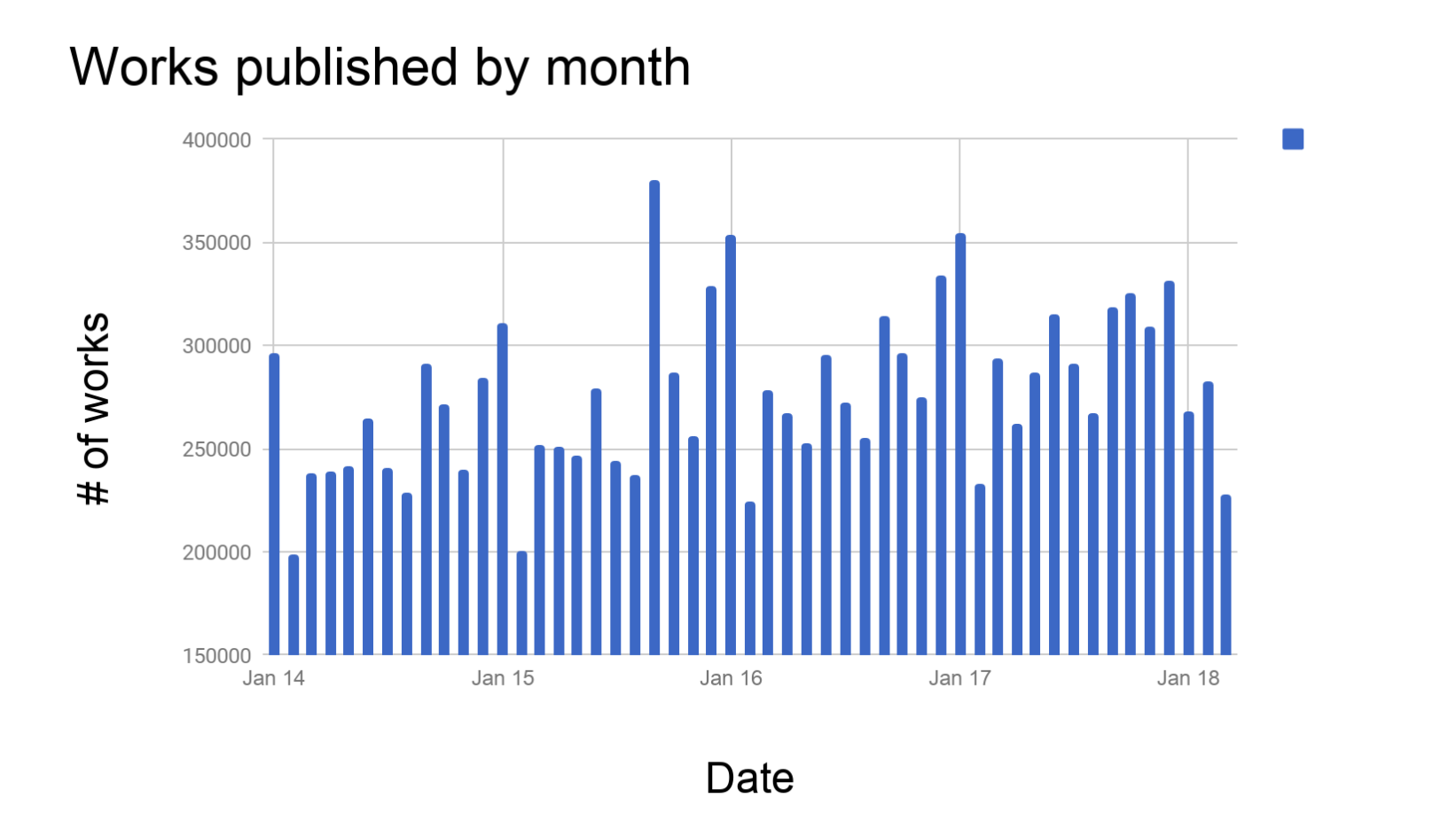
Each year brings with it a significant spike, an influx of new entrants, perhaps reflecting an increase in submissions at the end of the previous year. After January, volume drops down dramatically and gradually rises once more over the course of the year. We see smaller spikes at the March, June, and September mark. (Since this was a brief exercise, I did not dive into any formal research conducted on the nature of publishing cycles.)
The next question is a look at how the population is broken up into different demographics. For this, I analyzed four key sub-populations of ORCID, funding information, license, abstract metadata. The following graph shows the percentage of new parties (i.e., works registered at Crossref containing these metadata) across four specific segments.
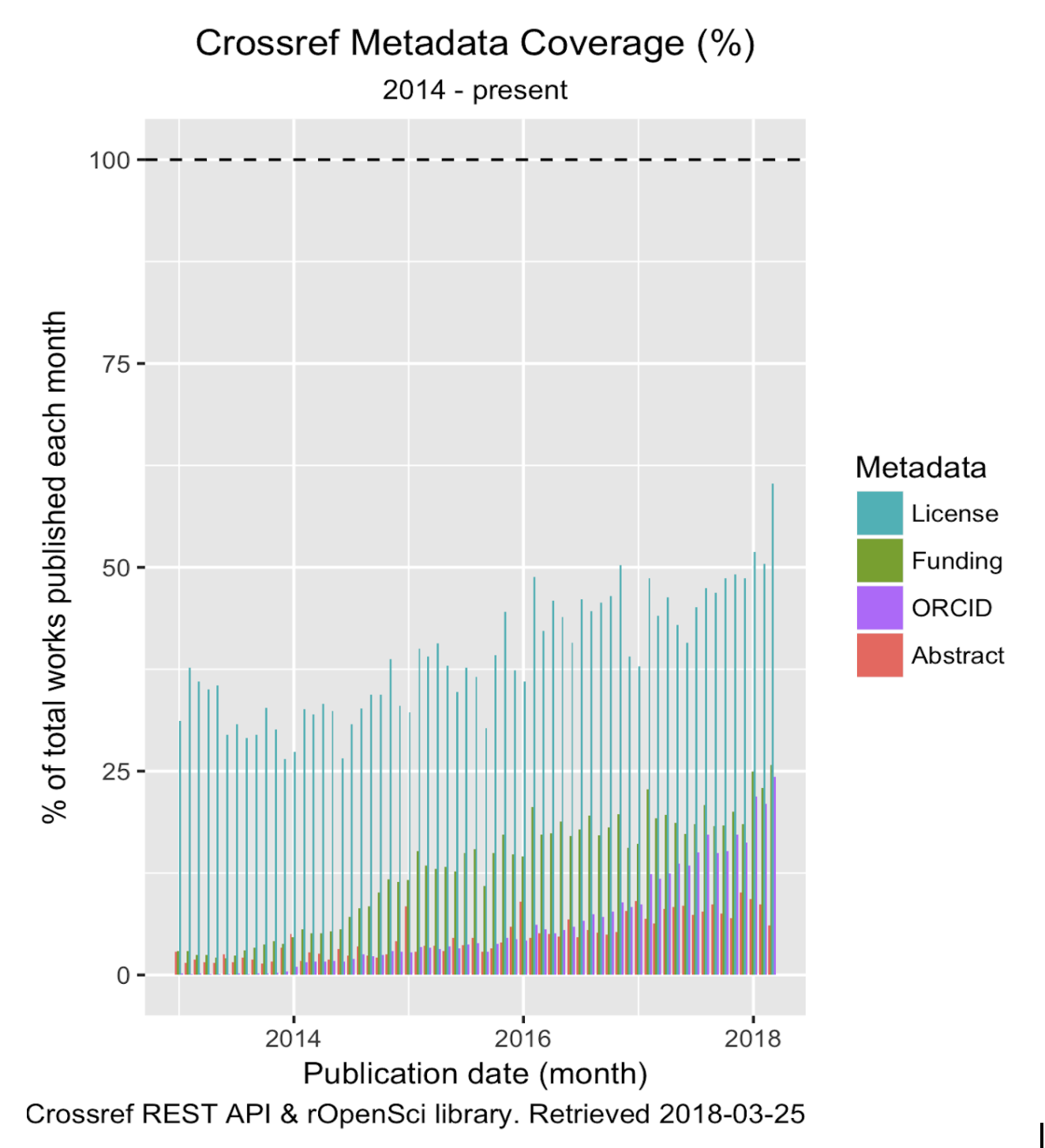
I ran Karthik Ram’s script which employed rOpenSci’s r client for the Crossref REST API. Data are based on publication date rather than deposit date and represent all updates to the metadata record for the baseline view.
The census graph shows extensive empty space on the top half, indicating there is ample room for continual growth in these communities. The ORCID population is expanding the fastest, followed by license and funding. Abstracts are a minority group and quite visibly needs a population boost here in Crossref-land.
This view does not capture the percentages across record types nor does it take into account the differential rate of growth between record types (e.g., journal article, book, report, conference proceeding, dissertation, dataset, component, posted content, peer review) as the Crossref corpus has grown. While ORCID, funding, and license information are available for all full record types (viz., excludes components), this matters for abstracts. Abstracts are part of the metadata schema of all relevant record types. This excludes those which do not apply: dataset, component, and peer reviews. All things considered though, the relative impact on the total percentage of metadata deposited (or not deposited) is miniscule given the small sums for these works.
Calling the real demographers & cartographers
This mini-pseudo-lustrum was the result of a few hours of play. The graphs have raised more questions than answers. We welcome more serious and earnest efforts to dive into the metadata and conduct a more detailed, reliable investigation on the size, distribution and composition of the population through our REST API. Next month, we will roll out reports on metadata coverage based on individual members.
This “play” census came out of a session with Karthik Ram, one of the founders of rOpenSci, as we talked about struggle to build better tools for researchers. (rOpenSci is an exciting and influential non-profit that builds open source software for research with a community of users and developers and educates scientists about transparent research practices.) With each round of cocktails, it became clear that a critical subset of the issues boiled down to the problem of limited information about research publications. Why, that is what Crossref does! Indeed. Publishers register their content with Crossref and provide the metadata about the works they publish.
Over the past few years, we have been working with our members to broaden the coverage of the metadata as well as improve their metadata quality. This issue is not exclusive to Crossref - Metadata 2020 rallies stakeholders across the research enterprise to push for change together.
To represent the full breadth and depth of the scholarly communications enterprise, Crossref aims to capture the richness of what our members publish through the content they register. So publishers, powerfully represent your services and make sure your metadata is complete and correct for discovery systems, indexing platforms, research evaluation systems, analytics tools, and the great number of Crossref metadata consumers far and wide.





