Retractions and corrections from Retraction Watch are now available in Crossref’s REST API. Back in September 2023, we announced the acquisition of the Retraction Watch database with an ongoing shared service. Since then, they have sent us regular updates, which are publicly available as a csv file. Our aim has always been to better integrate these retractions with our existing metadata, and today we’ve met that goal.
This is the first time we have supplemented our metadata with a third-party data source.
As a provider of foundational open scholarly infrastructure, Crossref is an adopter of the Principles of Open Scholarly Infrastructure (POSI). In December 2024 we posted our updated POSI self-assessment. POSI provides an invaluable framework for transparency, accountability, susatinability and community alignment. There are 21 other POSI adopters.
Together, we are now undertaking a public consultation on proposed revisions for a version 2.0 release of the principles, which would update the current version 1.
https://0-doi-org.libus.csd.mu.edu/10.13003/axeer1ee
In our previous entry, we explained that thorough evaluation is key to understanding a matching strategy’s performance. While evaluation is what allows us to assess the correctness of matching, choosing the best matching strategy is, unfortunately, not as simple as selecting the one that yields the best matches. Instead, these decisions usually depend on weighing multiple factors based on your particular circumstances. This is true not only for metadata matching, but for many technical choices that require navigating trade-offs.
Looking back over 2024, we wanted to reflect on where we are in meeting our goals, and report on the progress and plans that affect you - our community of 21,000 organisational members as well as the vast number of research initiatives and scientific bodies that rely on Crossref metadata.
In this post, we will give an update on our roadmap, including what is completed, underway, and up next, and a bit about what’s paused and why.
Many researchers want to carry out analysis and extraction of information from large sets of data, such as journal articles and other scholarly content. Methods such as screen-scraping are error-prone, place too much strain on content sites and may be unrepeatable or break if site layouts change. Providing researchers with automated access to the full-text content via DOIs and Crossref metadata reduces these problems, allowing for easy deduplication and reproducibility. Supporting text and data mining echoes our mission to make research outputs easy to find, cite, link, assess, and reuse.
In 2013 Crossref embarked on a project to better support Crossref members and researchers with Text and Data Mining requests and access. There were two main parts to the project:
To collect and make available full-text links and publisher TDM license links in the metadata.
To provide a service (TDM click-through service) for Crossref members to post their additional TDM terms and conditions and for researchers to access, review and accept these terms.
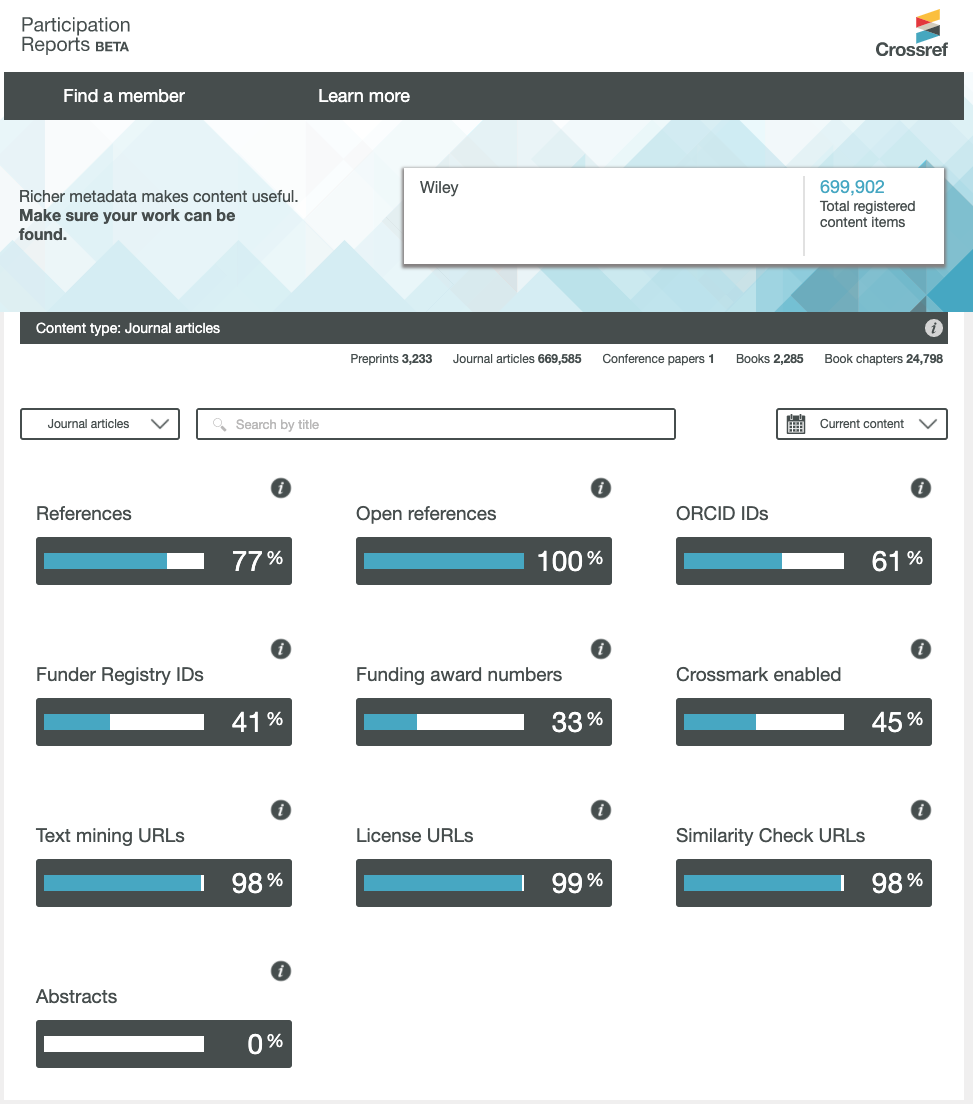
To date, 37.5 million works registered with Crossref have both full-text links and TDM license information. We continue to encourage all members to include full-text links and license information in the metadata they register to assist researchers with TDM. You can see how each member is doing via its Participation Report (e.g. Wiley’s).
Members are also making subscription content available for text mining (temporarily or otherwise) for specific purposes, such as to help the research community with its response to COVID-19. Back in April we highlighted how this can be achieved by including:
A “free to read” element in the access indicators section of publisher metadata indicating that the content is being made available free-of-charge (gratis)
An assertion element indicating that the content being made available is available free-of-charge.
To access Crossref’s click-through tool for text and data mining, users could log in via their ORCID iD. They could then review TDM license agreements posted by Crossref members and accept, reject or postpone their decisions until later. Having agreed to a publisher’s terms and conditions this action was logged against the user’s API token which they could use when requesting full-text from the publisher.
Since the pilot in 2014, only 2 publishers have continued with the tool and fewer than 300 API tokens have been issued.
Publishers have since developed their own mechanisms for managing TDM requests. The introduction of UK (2014) / EU (2019) copyright exceptions for TDM has significantly reduced the number of requests and at the same time, more and more content is published under an open access license.
Given the low take-up of the click-through by both publishers and researchers, its goals are no longer being met. Therefore we will retire the TDM click-through in December 2020. Until that date, it will still operate for the two publishers and various researchers who use it while they finish implementing their alternative plans.
Crossref will continue to collect member-supplied TDM licensing information in metadata for individual works, and researchers can continue to find this via the Crossref APIs.