17 minute read.Metadata beyond discoverability
Metadata is one of the most important tools needed to communicate with each other about science and scholarship. It tells the story of research that travels throughout systems and subjects and even to future generations. We have metadata for organising and describing content, metadata for provenance and ownership information, and metadata is increasingly used as signals of trust.
Following our panel discussion on the same subject at the ALPSP University Press Redux conference in May 2024, in this post we explore the idea that metadata, once considered important mostly for discoverability, is now a vital element used for evidence and the integrity of the scholarly record. We share our experiences and views on the metadata significance and workflows from the perspective of academic and university presses – thus we primarily concentrate on the context of books and journal articles.
The communication of knowledge is facilitated by tiny elements of metadata flitting around between thousands of systems telling minuscule parts of the story about a research work. And it isn’t just titles and authors and abstracts – what we think of as metadata has really evolved as more nuance is needed in the assessment and absorption of information. Who paid for this research and how much, how exactly did everyone contribute, what data was produced and is it available for me to reuse it, as well as, increasingly, things like post-publication comments, assertions from “readers like me”, who has reproduced this research or refuted these conclusions.
Different types of published works are described by different types of metadata – journal articles, book chapters, preprints, dissertations. And those metadata elements can be of varying importance for different users. In this article, we will talk about metadata from the perspectives of four personas highlighted by the Metadata 20/20:
- Metadata Creators, who provide descriptive information (metadata) about research and scholarly outputs.
- Metadata Curators, who classify, normalise and standardise this descriptive information to increase its value as a resource.
- Metadata Custodians, who store and maintain this descriptive information and make it available for consumers.
- Metadata Consumers, who knowingly or unknowingly use the descriptive information to find, discover, connect, and cite research and scholarly outputs.
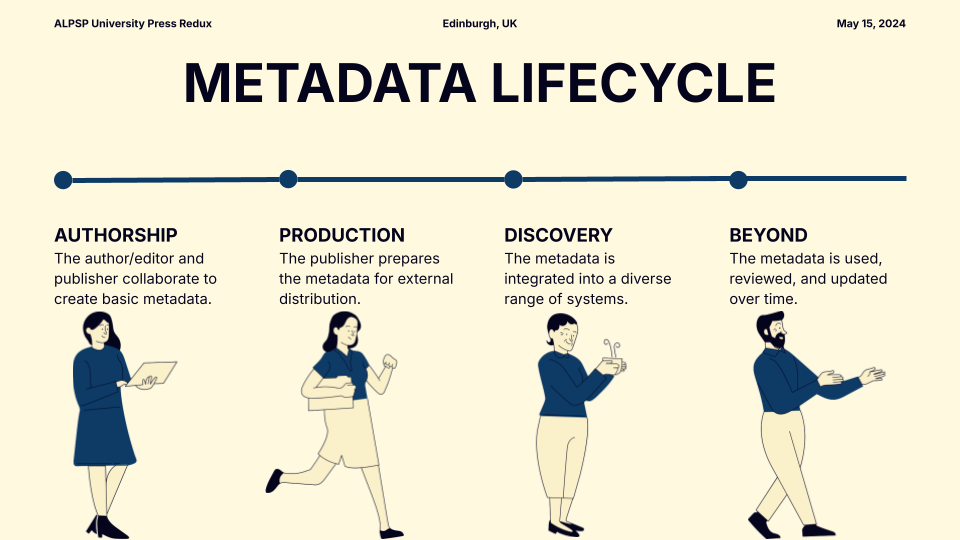
Our approach delineates the metadata lifecycle, from authorship, through production, discovery and through continuous curation. Though some of the metadata is generated outside of that linear process, and much happens before the authorship step, we see it as a clear and useful breakdown of how metadata contributes to a new piece of content.
Authorship
The first stage in the metadata lifecycle, authorship, is just the beginning of a dynamic process with many collaborators. A formative piece of the puzzle, authorship involves the authors or contributors, the editorial team and/or the marketing team and this is when the shape of the project and its metadata takes form. During this stage, the book or journal’s metadata exists only between the originators and the publisher, allowing the most opportunity for creativity and enhancement. Once the metadata reaches the next checkpoint along the lifecycle and is sent out externally, it’s more difficult and riskier to make major changes to the key metadata elements. In scholarly monograph publishing especially, we have the advantage of longer production lead times during which to amend and manipulate metadata during this stage.
At this stage, authors may have ideas of titles, subtitles and descriptions and it is up to the editors and other team members at the publisher to think strategically about how this can be optimised. The marketing and sales teams may be thinking about how the abstracts, keywords, and classifications can be best optimised for the web, leading to increased sales. Discoverability and interoperability of metadata for a book or journal, especially the use of persistent identifiers, is beneficial both for the author – in that their book is easily discovered, used, and cited – and for the publisher – increased visibility, sales, and usage.
Current challenges at the authorship stage include changing goalposts for metadata standards and accessibility requirements, which also have knock-on effects in subsequent stages in the metadata lifecycle. One of the key challenges with these is that they require buy-in from multiple players to keep up with and amend, and publishers must think closely about how these changes may affect metadata workflows for books at different stages of publication.
Production
As a book or journal article comes into production, it’s time to update and release the metadata to retailers, libraries, data aggregators and distributors. The metadata should be updated and checked to make sure that it’s still a good reflection of the product or the content that it describes and complete enough to release, including a final cover image in the case of books.
This is still very much a collaborative effort with multiple roles involved. Technical details, such as spine width, page extents, and weight, are added, capturing the final specification. The editorial team may update metadata entered into systems earlier in the process. For example reviewing the prices, updating subject classification codes or amending the chapter order. If any of the content is to be published open access, appropriate licensing and access metadata need to be included, so that users of the content are clear about what they can (and can’t!) do with it.
Metadata that’s not yet captured upstream can be added or enhanced. For example, vendors already involved in the production process can verify that persistent identifiers (PIDs) are present and correct in funding metadata.
More and more metadata elements are being requested by supply chain partners. For example, new requirements being introduced to provide commodity codes, spine width, carton quantities, gratis copy value and country of manufacture. There may be differences in metadata depending on the methods of production. For example, country of manufacture will be supplied differently when using traditional print methods where the whole print run is carried out at a location, or where a title is manufactured print on demand and the location of printing is determined by the delivery address.
In an XML-first workflow, metadata can be captured with the content files to aid with discovery. This usually requires multiple systems, both internal and external. These systems need to be able to work together to ensure that only up-to-date metadata is used. Metadata will change throughout the production process, whether it’s the publication of an accepted manuscript through to the final version of record, or pre-order information to the published version, so updates need to feed out regularly.
The right metadata needs to go to the right recipient. Some is not useful or cannot be processed by certain recipients. For example, a printer, retailer, librarian or data aggregator each have their own needs and use cases and may receive and process metadata in different formats or require different fields.
Discovery
Discovery is the series of actions taken by an end user to retrieve and access relevant content they do not know about. Discovery can happen everywhere: Google (a search engine), a library catalog, a publisher platform, etc. However, Discovery is associated with using Discovery systems in the academic sector.
The technological landscape of libraries has developed in the last 15 years. Discovery systems are tools libraries subscribe to in order to allow their end users to have one search experience within their library holdings. It is paramount for librarians that library collections are used; hence, it is very important for them that the discovery system of their choice contains all the relevant metadata. Libraries expect their discovery service to include their content coverage as comprehensively as possible. Content items not represented or misrepresented in a discovery system create challenges to libraries in how they might otherwise ensure that these materials are discovered and accessed.
Libraries’ adoption and usage of discovery systems are surrounded by the belief that the great benefits of this technology are the one search box and the configuration flexibility, which are the most important benefits. Libraries invest a significant amount of money in discovery services. The increase in usage is the success indicator of this adoption and a positive return on investment.
The backbone of discovery systems is formed by three crucial elements: a user interface, a metadata index, and a link resolver or Knowledge Base. These elements, along with a back-end control panel for librarian configuration, are the key components that enable the discovery process.
The discovery index, a database storing descriptive data from various content providers, data sets, and content types, is a testament to the collaborative efforts of content providers and discovery systems vendors. Their work under the Discovery Metadata Sharing partnership agreements, which establish the format, scope, frequency, and support of the collaboration, is instrumental in meeting librarians’ expectations.
The discovery metadata integration processes have settled down for most cases in these two metadata delivery workflows.
Metadata for the index of discovery: Discovery systems have traditionally made efforts to work with various metadata formats like MARC, proprietary templates, etc., but the preferred format is XML. This metadata could include all the bibliographic information data, including index terms and full text at the article and chapter level.
Metadata for link resolvers and Knowledge bases: Knowledge bases are tools that contain information about what is included in a product, packages, and/or databases. KBART is the preferred format in this area. It includes a set of basic bibliographic descriptions at the publication level and linking information for direct and OpenURL syntaxes.
Frequency
The delivery channels vary, and the frequency could vary daily to yearly, depending on the publication schedule.
Scope
Library collections include various content types, including archival materials, open access, and multimedia alongside the more traditional books and periodicals. Different content types will require different metadata elements to make a comprehensive discovery-friendly description, and the metadata elements will impact the formats in use.
Discovery services will receive this data and prioritise uploading. They will select and manipulate the required metadata elements according to their system requirements. These metadata tweaks and selections are not always communicated to the content providers and/or libraries.
Ultimately, librarians decide which metadata will be visible on their discovery tool and the linking methods of their choice.
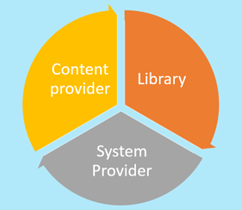
As described, Discovery is a complex area where the activities of its main stakeholders are interconnected. The success of the end users’ discovery journey from search to access depends on the successful integration, implementation, and maintenance of the discovery systems. This necessitates a combined effort from the three discovery stakeholders: content providers, discovery system providers, and libraries. Their collaborative work is not just crucial, but integral to supporting discovery and fulfilment in the most efficient manner possible. Your active involvement in this process is what makes it successful.
How do we ensure discoverability?
Electronic resources do not exist in isolation but are assessed and used depending on their level of integration in the discovery landscape where libraries and patrons are active.
From a content provider’s perspective, discoverability is about the number and efficiency of entry points to our products created in third-party discovery products.
The level of discovery integration has a direct impact on sales and upsell opportunities. Products that are not discoverable are difficult to work with, and the opposite is true for products that are considered discoverable. Your role in ensuring discoverability directly influences the user experience and sales, making your work crucial and impactful.
The term ‘Discoverability’ is critical in discovery library systems. It refers to the extent to which eResources are searchable in a discovery system, and it directly influences the ease with which users can find the information they need, thereby enhancing their overall experience.
In practical terms, the degree of discoverability will be impacted by the quality of the metadata supplied, the transformations the metadata suffers in the integration process to discovery systems, and the configuration’s maintenance.
The general principles of metadata quality also apply in this area: accuracy, completeness, and timely delivery. Your attention to these principles is crucial to contributing to the effectiveness of the discovery process. Metadata enrichment practices like identifiers and standards are also applicable. Your meticulous attention to detail in maintaining metadata quality ensures the effectiveness of the discovery process.
Discovery as a mindset in the publishing process will increase discoverability, as it will be influenced by product designs (whether the content is linkable) and which metadata outputs are possible. For example, author-generated index terms will be more effective for meeting research search terms, and detailed article titles will probably be more discoverable than general titles.
Finally, all the integration, descriptive metadata, configurations, etc., leave much room for errors. The flow is complex; on occasion, the products and content are more complicated to describe than tools can handle, and there are millions of holdings per library to manage. Constant maintenance and troubleshooting are crucial elements to maintaining and increasing discoverability.
In the lead-up to publication, finalising rich complete metadata can seem like establishing a fixed set of information. Post-publication, however, the metadata workflow should be dynamic, able to evolve to keep pace with new demands and opportunities. Think of metadata as a journey rather than a one-time destination, and look at ways to futureproof your metadata by actively adapting to some of the following types of change.
Changing Publisher Goals and Product Needs
Metadata should align with changing priorities for a publisher. Developing new formats, shifts in commissioning focus or building new distribution partnerships may require metadata updates. For instance, re-releasing content in audiobook form or digitising a backlist title warrants a metadata review to ensure current and prospective readers find accurate, relevant information.
Advances in technology, from artificial intelligence to emerging metadata standards, offer enhanced possibilities for capturing and updating metadata. AI, for example, can help enrich metadata with more precise subject tagging, while new metadata formats may offer greater compatibility across platforms and discovery services. Staying current with these tools can help publishers manage metadata more efficiently and enhance discoverability.
Changing Societal Values
As society evolves, so do expectations for inclusive and socially responsible metadata. Utilising new categorisation codes, such as those for the United Nations Sustainable Development Goals, can align metadata with emerging social goals. Similarly, publishers may need to revisit keywords and category codes to reflect language changes, balancing the integrity of historic records with the need for current, appropriate terminology.
Changing Industry Priorities
Commitments to accessibility and sustainability have prompted developments in metadata. Increasingly, publishers need to be able to use metadata to build a record of sustainable production methods, such as paper sources, printing methods or ink types. New metadata fields for accessibility specifications will also support more inclusive reader experiences going forward. Metadata will play an increasingly vital role in meeting industry standards for accessibility, EUDR and EAA compliance, and environmental transparency.
Changing Customer and Librarian Expectations
Finally, as the metadata expectations of customers grow and the nature of roles and responsibilities in library and collection management professions develops, teamwork and making good use of available resources are essential. Publishers don’t have to tackle this alone. Working with organisations such as Crossref or Book Industry Communication (BIC), signing up to newsletters and webinars, and forming an in-house discovery group are all great ideas for sharing ideas and best practice, and ensuring your metadata workflow is adaptable and responsive. Be part of the conversation now rather than struggling to keep up down the line!
JM: Metadata that establishes permanence is a real opportunity in a digital landscape where content can move or be taken down, links can rot, website certificates can expire. Persistent identifiers like ORCiDs for people and DOIs for content are key examples of metadata that establish enduring routes to, and provenance of, published digital content.
KM: Metadata creation, maintenance and change has long been seen as a manual process. AI tools offer a real opportunity for metadata creation and review, especially for keywords and classification codes, at a scale and speed that has the potential to transform metadata workflows. Especially for backlist transformation, AI could offer real opportunities in this area. A challenge we face for monograph metadata more specifically is that much of the scholarly metadata infrastructure is built around the journal article, and it can be difficult to fit longer form content into these systems of discovery.
MT: Metadata is crucial. Good metadata (complete, accurate, and timely) is the base for smooth integrations and easy discovery interactions with eResources. Bad metadata (inaccurate, incomplete, late) will be the main reason for undiscovered content. At this point, the eResources industry is still based on different versions of the same metadata, which is the leading cause of problems. It is probably time to start considering a unique record approach. This unique record, which will be complete and accurate, could be used by different systems for different purposes. I know there are many details to define here, but if you think about it, it is not impossible and could solve the many known issues.
SP: Validation of data is really important, so choosing or building a system that’s set up to do this is an important foundation. It’s straightforward to check for completeness of fields and I run daily checks on our book metadata to make sure there’s nothing missing in the files feeding out. Quality can be more challenging to monitor. Feedback from data recipients is key, and accreditation schemes such as the BIC Metadata Excellence Award are a great way to benchmark progress. Good training and clear documentation help to make sure that everyone involved in creating and updating metadata understands exactly what they need to do and the standards they need to meet.
KM: Earlier this year we completed a year-long data cleansing project as part of our move to a new title management database. This gave us the time to address gaps in backlist metadata as well as to identify any inconsistencies across records for the same book, and enrich key metadata fields like classification codes, keywords and PIDs. For frontlist titles, each person owns a number of fields to ensure they are complete before a book’s metadata is distributed – some of these have validation tools which will prevent a book’s metadata from being sent out unless it is complete.
MT: Strict and consistent internal processes are essential to ensure quality and completeness. Following the different standards and industry recommendations helps to keep the quality at high standards. Random manual checks and system-based checks help to ensure everything is good. We carry out projects where we work with specific aspects of the metadata. This building-blocks approach ensures the different data layers are as good as possible. As with any project, metadata projects should have specific goals, outcomes, resources, and documentation.
JM: Take any available opportunities to find out what people think of your metadata – via library conferences, institutional customer feedback, and by working with the library team at our home institution, we’ve had some really useful and interesting conversations about MUP’s metadata and where we can improve it to make it as relevant as possible for different stakeholder needs.
MT: Customers and Discovery partners will inform us if something is incorrect. Usage data is also a good indicator of how healthy our metadata is. Following industry standards is another good reference point for assessing the metadata. Finally, the metadata is only good when we know what we want to use it for. So, always considering what we are trying to achieve helps us understand how effective the metadata is.
KM: As the others have noted here, and we represent a range of different types and sizes of publishers, measuring the direct impact of metadata is an ongoing challenge. We think about the different end users who might encounter our metadata further down the supply chain – retail customers searching on Amazon, librarians filtering results on purchasing platforms, researchers finding our books and journals through citations on popular online search engines – and consider what elements of our metadata might help reach those people in the right ways.
JM: Ideally, you’ll see an uplift in sales or usage for every metadata element that you add, review or expand, although it can be challenging to quantify and prove a direct correlation between richer metadata and higher revenue or discoverability, as there are will be other factors involved. For my Operations team, what is certain is that richer, more comprehensive metadata means fewer errors are thrown up by the distribution systems and feeds we use, which means colleagues save time and gain productivity by not having to resolve and rerun failed jobs, chase missing information from other teams, or manually send information to third parties. My job is also made easier because things like size and weight of every printed product are recorded in our bibliographic database as standard, easy to report on and analyse, which helps with forecasting costs for inventory storage or shipping. Metadata can be powerful.