8 minute read.Now put your hands up! (for a Similarity Check update)
Today, I’m thinking back to 2008. A time when khaki and gladiator sandals dominated my wardrobe. The year when Obama was elected, and Madonna and Guy Ritchie parted ways. When we were given both the iPhone 3G and the Kindle, and when the effects of the global financial crisis lead us to come to terms with the notion of a ‘staycation’. In 2008 we met both Wall-E and Benjamin Button, were enthralled by the Beijing Olympics, and became addicted to Breaking Bad. And lest we forget, 2008 was also the year in which Beyoncé brought us Single Ladies; in all its sassy hand-waving, monochrome glory. For Crossref though, 2008 holds another important milestone as it was the year we launched our Similarity Check initiative. Today, the artist formerly known as CrossCheck provides our members with cost-effective access to Turnitin’s powerful text comparison tool, iThenticate.
Fast forward nearly a decade, and it’s wonderful to see just how Similarity Check membership has grown in the nine years since launch; from 16 original members in 2008 to over 1,300 today.
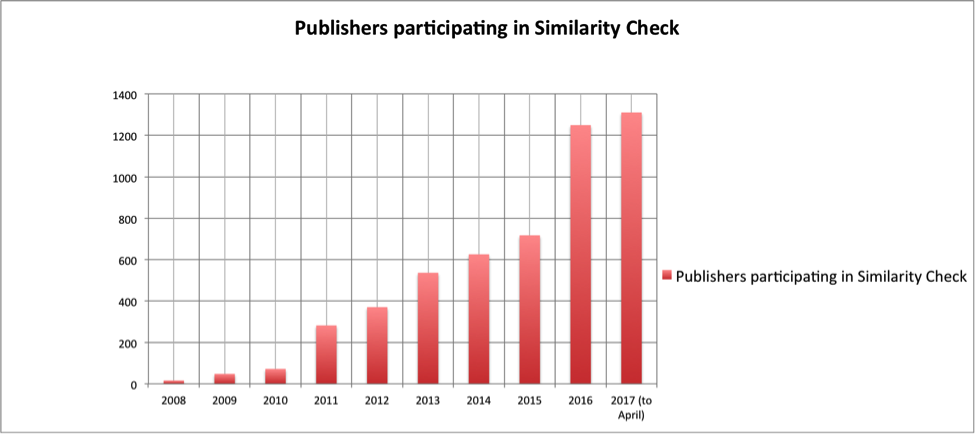
Figure 1.1 The number of publishers participating in the Similarity Check service each year between 2008 – 2017 (to April)
Usage of iThenticate is also consistent with this growth in membership, and throughout 2016 our members checked over four million manuscripts for similarity using the tool. As Similarity Check members contribute their full-text content into Turnitin’s database, this increase in membership also has a dramatic impact on the volume of content indexed by Turnitin. Today, members can compare their manuscripts against Turnitin’s database of over 60 million full-text works provided by Similarity Check members. With over 88 million works currently registered with Crossref, this means that 68% of all content deposited with us is now available for comparison in iThenticate.
Over the years we have worked very closely with Turnitin to help champion new iThenticate feature developments that best support our member’s use of the tool as a core function of their editorial workflow. Many of our members too have also worked together with Turnitin to provide feedback on user experience and design.
Below, Turnitin’s Product Manager for iThenticate, Sun Oh, shares an insight into their research process and how Similarity Check member’s feedback has been critical in developing new and improved functionality in iThenticate.
Read on to learn more from Sun…

Sun Oh is a Senior Product Manager at Turnitin. She is currently the Product Manager for iThenticate and backend systems including the Content Intake System and similarity reports.
Last year we surveyed our Crossref customers to find out what Similarity Check improvements they would like to see and noticed a recurring request for the ability to compare two or more personally sourced documents.
We were intrigued and decided to run with it. We contacted the respondents who had asked for this, and started conversations to find out more. This helped us gather invaluable data, which in turn helped us to build the feature based on real use cases and with a clear view of what was wanted.
The design prototypes were reviewed for usability and effectiveness each step of the way by the respondents and once we had the feature up and running, those who requested it in our initial survey were among the first to trial it.
We’re thrilled to announce that we’ve now launched the new Doc-to-Doc comparison feature, available through iThenticate’s native interface. Simply select the Doc-to-Doc comparison upload method from the document submission panel.
If you are a Crossref member using Similarity Check, you have exclusive early access to this new feature, which allows you to use iThenticate’s powerful similarity check functionality and apply it to your own, private documents.
How does Doc-to-Doc Comparison work?
Doc-to-Doc comparison allows users to upload one primary document and compare it against up to five other documents.
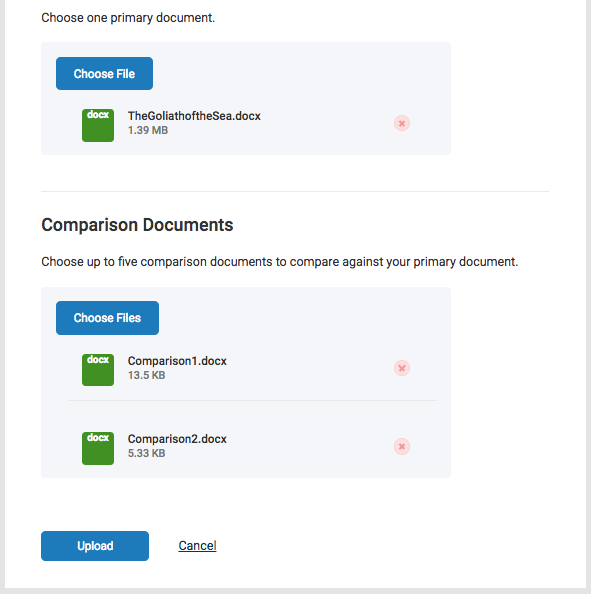
Figure 1.2 The document upload screen for Doc-to-Doc comparison
When the upload is complete, a similarity score is generated for the primary document based on the amount of similar content found in the comparison documents. A full comparison report is also available.
The comparison report will open in the document viewer, and will display the primary document along with a list of the comparison documents and with their similarity percentage. If one of the comparison documents doesn’t include text that matches the primary document, iThenticate will still display it anyway, with a 0% score, allowing users to rule it out of their inspection. The similarity report will be stored securely in the user’s folder until they delete it.
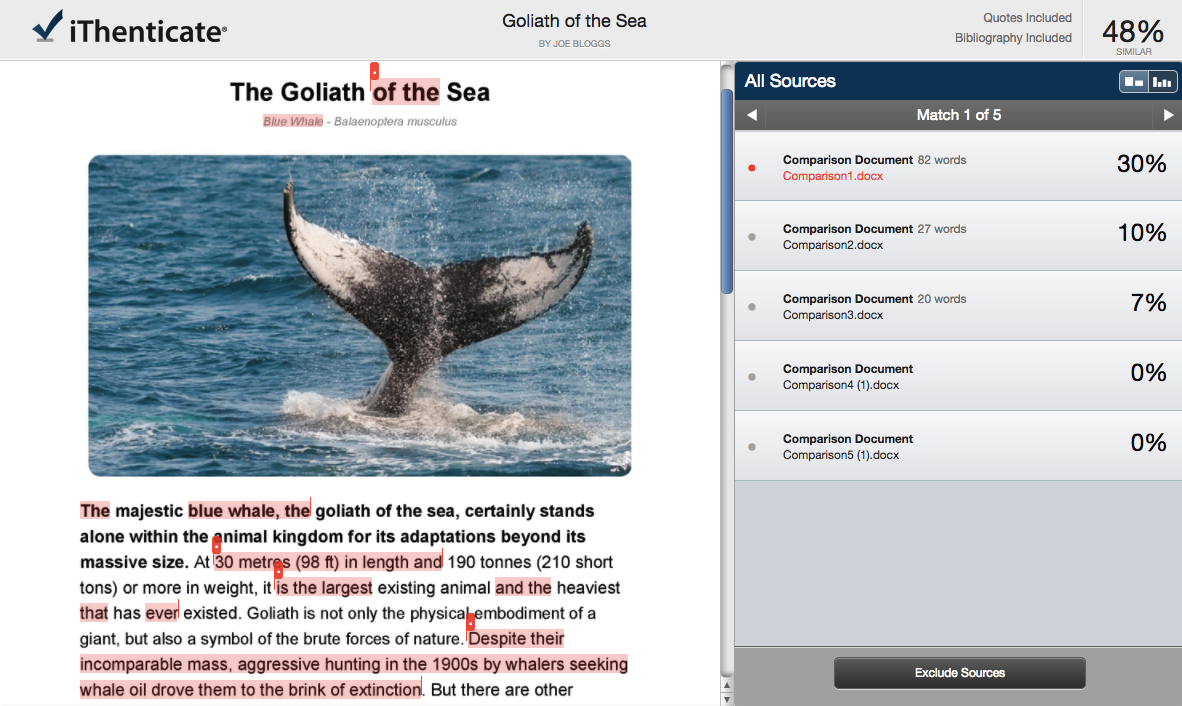
Figure 1.3 Similarity report for Doc-to-Doc comparison
As these documents will not be stored in a shared database, they won’t affect the similarity score of any future submissions. Primary and comparison documents remain completely private and will not be indexed into the shared iThenticate content database.
To get a better idea of how Doc-to-Doc comparison works, check out the iThenticate feature guide on the Turnitin website.
Start using Doc-to-Doc Comparison now!
If you’re a Crossref member using Similarity Check, you can log in to your iThenticate account now and select the Doc-to-Doc comparison link on the homepage.
What else is new in iThenticate in this new release?
New Look
In addition to Doc-to-Doc comparison, we decided to refresh the look and feel of iThenticate; the same tools our users know and trust, now with a modern interface. Users will also notice that iThenticate now has more readable font and friendlier styling throughout.
Report Mode Memory
To make life easier, iThenticate now remembers whether users were in the All Sources or Match Overview mode when they last used the Document Viewer. iThenticate will then open documents in this mode automatically hereafter.
Improved Submission Process
We’re also enhancing our submission process by making the upload requirements more inclusive. We’ve increased the possible file size limit from 40MB to 100MB when uploading to either the database or to Doc-to-Doc comparison, and PowerPoint (.ppt) and Excel (.xlsm) file formats are now accepted.
Developments completed in 2016
If Similarity Check members haven’t had a chance to check out the improvements we introduced in iThenticate throughout 2016, here’s a quick recap. You can always find our updates on the What’s New page of the iThenticate website.
Download User List
The ability for administrators to download a list of all the users in their account has been added. This list will allow administrators to easily send emails to users.
Similarity Score Calculation Update
We updated how the similarity score is calculated when bibliographic material is excluded from a similarity report. Now, when bibliography exclusion is enabled, the word count of the bibliography is not included when calculating the overall percentage. This update to the similarity report calculation helps to provide users with a more accurate similarity score.
Improved Security
We are fully committed to keeping user’s data safe and secure at all times. To that end, we’ve added additional security logging, put in measures to enforce stronger passwords, and enabled Captcha after failed login attempts.
Faster Report Generation
We’ve increased the number of resources dedicated to the generation of similarity reports for our iThenticate service. As a result, users should see faster turnaround times for similarity reports.
Support for Eight Additional Languages
The iThenticate user interface is now available in eight additional languages: German, Dutch, Latin American Spanish, Brazilian Portuguese, Italian, French, and both Simplified & Traditional Chinese. When adding new users to an account, administrators can specify the language of the new user, which will then send a welcome email in the selected language. Individual users can also set their preferred language by selecting a language from the Language dropdown in the Settings menu.
Content Intake System
We’ve developed a new Content Intake System which enables our publication content database to scale so that our users can compare against a constantly growing database of the most recently published content. This allows us to index Similarity Check members’ data in a much more reliable and efficient way than legacy intake methods. And recently, we’ve made the collecting and processing of content from Crossref members using Similarity Check even faster by parallelising our processors. This means that we have more processors running simultaneously to process data.
By removing the need for crawling, we will also minimize our impact on traffic to a Similarity Check member’s public-facing website. The Content Intake System is able to directly collect full text URLs from members DOI metadata. This results in a huge reduction in the time it takes from when a publisher first deposits a new DOI with Crossref, to when the content is indexed by us into our full-text publication database. To date, we’ve been able to index the content associated with 60 million Crossref DOIs, and have indexed more than 165 million published works in total which submissions are compared against in iThenticate.
Walker (web crawler)
We’ve developed a new web crawler. Referred to as “Walker”, the crawler makes it possible to provide quicker and more reliable similarity matches to content available on the web. Not to be confused with the Content Intake System mentioned above, Walker’s purpose is to crawl the public web and is not used for indexing full-text content from Similarity Check members.
Using Walker, we’re adding an average of nearly 10 million new web pages to our content database per day, ensuring we have the freshest internet content available to find matches against.
We’d love to get your feedback!
As we design and develop new features, we want to make sure we’re fully understanding Similarity Check member’s needs and would love the opportunity to engage with users for further research. If you’d like to sign up to participate in user research for upcoming feature developments, please take a few minutes to fill out our Feedback Program Form. We look forward to connecting with you!
For iThenticate technical and billing support, please email ccsupport@ithenticate.com
For questions about content indexing, please contact Gareth at gmalcolm@turnitin.com
For iThenticate product development questions, please contact Sun at soh@turnitin.com
- Sun Oh, Product Manager for iThenticate
**Thanks to Sun and the whole team at Turnitin for sharing this update.**
For more information about Similarity Check, visit our service page.
Want to join Crossref Similarity Check? Please contact our membership specialist.
Related pages and blog posts




