3 minute read.The Organization Identifier Project: a way forward
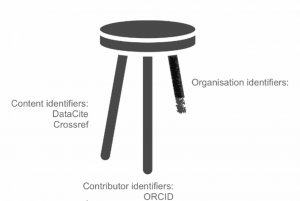
The scholarly communications sector has built and adopted a series of open identifier and metadata infrastructure systems to great success. Content identifiers (through Crossref and DataCite) and contributor identifiers (through ORCID) have become foundational infrastructure to the industry.
But there still seems to be one piece of the infrastructure that is missing. There is as yet no open, stakeholder-governed infrastructure for organization identifiers and associated metadata.
In order to understand this gap, Crossref, DataCite and ORCID have been collaborating to:
- Explore the current landscape of organizational identifiers;
- Collect the use-cases that would benefit our respective stakeholders in scholarly communications industry;
- Identify those use-cases that can be more feasibly addressed in the near term; and
- Explore how the three organizations can collaborate (with each other and with others) to practically address this key missing piece of scholarly infrastructure.
The result of this work is in three related papers being released by Crossref, DataCite and ORCID for community review and feedback. The three papers are:
- Organization Identifier Project: A Way Forward (PDF; GDoc)
- Organization Identifier Provider Landscape (PDF; GDoc)
- Technical Considerations for an Organization Identifier Registry (PDF; GDoc)
We invite the community to comment on these papers both via email (oi-project@orcid.org) and at PIDapalooza on November 9th and 10th and at Crossref LIVE16 on November 1st and 2nd. To move The OI Project forward, we will be forming a Community Working Group with the goal of holding an initial meeting before the end of 2016. The Working Group’s main charge is to develop a plan to launch and sustain an open, independent, non-profit organization identifier registry to facilitate the disambiguation of researcher affiliations.
Crossref Use Cases
Crossref has also been discussing the needs of its members over the last year and there is value in focusing on the affiliation name ambiguity problem with research outputs and contributors. In terms of the metadata that Crossref collects, something that is missing has been affiliations for the authors of publications. Over the last couple of years, Crossref has been expanding what it collects - for example, funding and licensing data and ORCID iDs - and this enables a fuller picture of what we are calling the article nexus. In order to continue to fill out the metadata we collect - and for our members to use in their own systems and publications - we need an organization identifier.
Another use case for Crossref is identifying funders as part of collecting funder data to enable connecting funding sources with the published scholarly literature. In order to enable the reliable identification of funders in the Crossref system we created the Open Funder Registry that now has over 15,000 funders available as Open Data under a CC0 waiver. While this has been very successful, it is a very narrowly focused registry and is not suitable for a broad, community-run organization identifier registry that addresses the affiliation use case. In future, our goal will be to merge the Open Funder Registry into the identifier registry that the Organization Identifier Working Group will work on.
By working collaboratively we can define a pragmatic and cost-effective service that will meet a fundamental need of all scholarly communication stakeholders.
Geoffrey Bilder will be focusing his talk at Crossref LIVE16 this week on this initiative, dubbed The OI Project. The talk is scheduled for 2pm UK time and will be live streamed along with the rest of that day’s program.