Retractions and corrections from Retraction Watch are now available in Crossref’s REST API. Back in September 2023, we announced the acquisition of the Retraction Watch database with an ongoing shared service. Since then, they have sent us regular updates, which are publicly available as a csv file. Our aim has always been to better integrate these retractions with our existing metadata, and today we’ve met that goal.
This is the first time we have supplemented our metadata with a third-party data source.
As a provider of foundational open scholarly infrastructure, Crossref is an adopter of the Principles of Open Scholarly Infrastructure (POSI). In December 2024 we posted our updated POSI self-assessment. POSI provides an invaluable framework for transparency, accountability, susatinability and community alignment. There are 21 other POSI adopters.
Together, we are now undertaking a public consultation on proposed revisions for a version 2.0 release of the principles, which would update the current version 1.
https://0-doi-org.libus.csd.mu.edu/10.13003/axeer1ee
In our previous entry, we explained that thorough evaluation is key to understanding a matching strategy’s performance. While evaluation is what allows us to assess the correctness of matching, choosing the best matching strategy is, unfortunately, not as simple as selecting the one that yields the best matches. Instead, these decisions usually depend on weighing multiple factors based on your particular circumstances. This is true not only for metadata matching, but for many technical choices that require navigating trade-offs.
Looking back over 2024, we wanted to reflect on where we are in meeting our goals, and report on the progress and plans that affect you - our community of 21,000 organisational members as well as the vast number of research initiatives and scientific bodies that rely on Crossref metadata.
In this post, we will give an update on our roadmap, including what is completed, underway, and up next, and a bit about what’s paused and why.
Continuing our blog series highlighting the uses of Crossref metadata, we talked to David Sommer, co-founder and Product Director at the research dissemination management service, Kudos. David tells us how Kudos is collaborating with Crossref, and how they use the REST API as part of our Metadata Plus service.
Introducing Kudos
At Kudos we know that effective dissemination is the starting point for impact. Kudos is a platform that allows researchers and research groups to plan, manage, measure, and report on dissemination activities to help maximize the visibility and impact of their work.
We launched the service in 2015 and now work with almost 100 publishers and institutions around the world, and have nearly 250,000 researchers using the platform.
We provide guidance to researchers on writing a plain language summary about their work so it can be found and understood by a broad range of audiences, and then we support researchers in disseminating across multiple channels and measuring which dissemination activities are most effective for them.
As part of this, we developed the Sharable-PDF to allow researchers to legitimately share publication profiles across a range of sites and networks, and track the impact of their work centrally. This also allows publishers to prevent copyright infringement, and reclaim lost usage from sharing of research articles on scholarly collaboration networks.
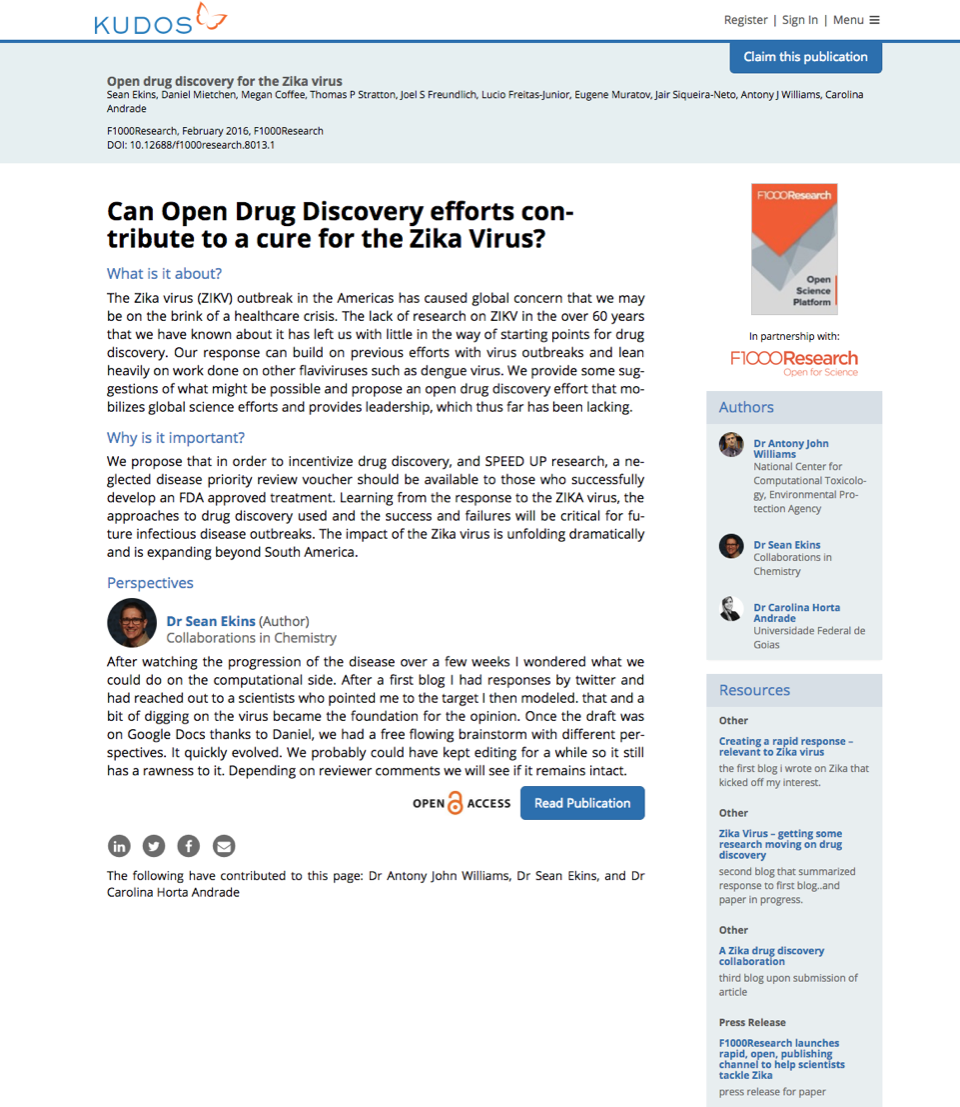
An example of a Kudos publication page showing the plain language summary
How is Crossref metadata used in Kudos?
Since our launch, Crossref has been our metadata foundation. When we receive notification from our publishing partners that an article, book or book chapter has been published, we query using the Crossref REST API to retrieve the metadata for that publication. That data allows us to populate the Kudos publication page.
We also integrate earlier in the researcher workflow, interfacing with all of the major Manuscript Submission Systems to support authors who want to build impact from the point of submission.
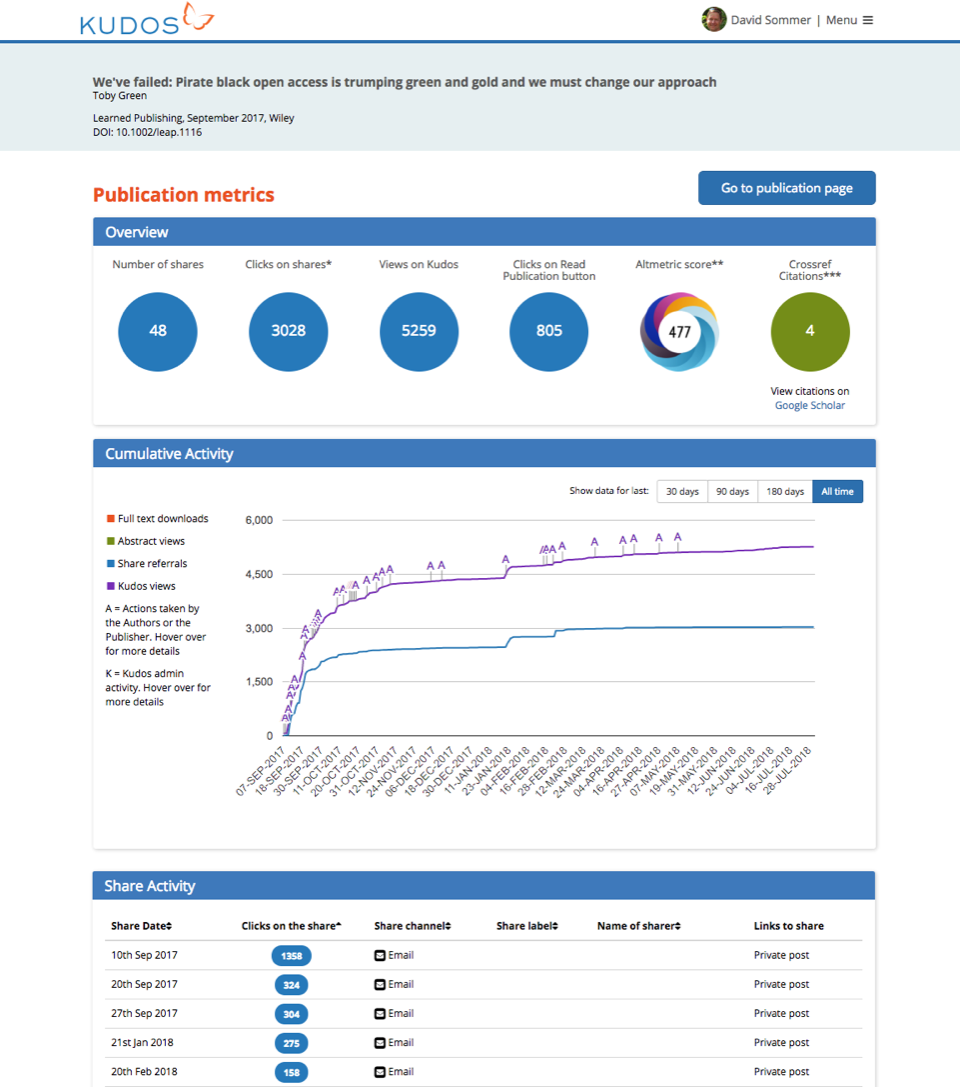
More recently, we started using the Crossref REST API to retrieve citation counts for a DOI. This enables us to include the number of times content is cited as part of the ‘basket of metrics’ we provide to our researchers. They can then understand the performance of their publications in context, and see the correlation between actions and results.
A Kudos metrics page, showing the basket of metrics and the correlation between actions and results
What are the future plans for Kudos?
We have exciting plans for the future! We are developing Kudos for Research Groups to support the planning, managing, measuring and reporting of dissemination activities for research groups, labs and departments. We are adding a range of new features and dissemination channels to support this, and to help researchers to better understand how their research is being used, and by whom.
What else would Kudos like to see in Crossref metadata?
We have always found Crossref to be very responsive and open to new ideas, so we look forward to continuing to work together. We are keen to see an industry standard article-level subject classification system developed, and it would seem that Crossref is the natural home for this.
We are also continuing to monitor Crossref Event Data which has the potential to provide a rich source of events that could be used to help demonstrate dissemination and impact.
Finally, we are pleased to see the work Crossref are doing to help improve the quality of the metadata and supporting publishers in auditing their data. If we could have anything we wanted, our dream would be to prevent “funny characters” in DOIs that cause us all kinds of escape character headaches!
Thank you David. If you would like to contribute a case study on the uses of Crossref Metadata APIs please contact the Community team.