We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
Continuing our blog series highlighting the uses of Crossref metadata, we talked to David Sommer, co-founder and Product Director at the research dissemination management service, Kudos. David tells us how Kudos is collaborating with Crossref, and how they use the REST API as part of our Metadata Plus service.
Introducing Kudos
At Kudos we know that effective dissemination is the starting point for impact. Kudos is a platform that allows researchers and research groups to plan, manage, measure, and report on dissemination activities to help maximize the visibility and impact of their work.
We launched the service in 2015 and now work with almost 100 publishers and institutions around the world, and have nearly 250,000 researchers using the platform.
We provide guidance to researchers on writing a plain language summary about their work so it can be found and understood by a broad range of audiences, and then we support researchers in disseminating across multiple channels and measuring which dissemination activities are most effective for them.
As part of this, we developed the Sharable-PDF to allow researchers to legitimately share publication profiles across a range of sites and networks, and track the impact of their work centrally. This also allows publishers to prevent copyright infringement, and reclaim lost usage from sharing of research articles on scholarly collaboration networks.
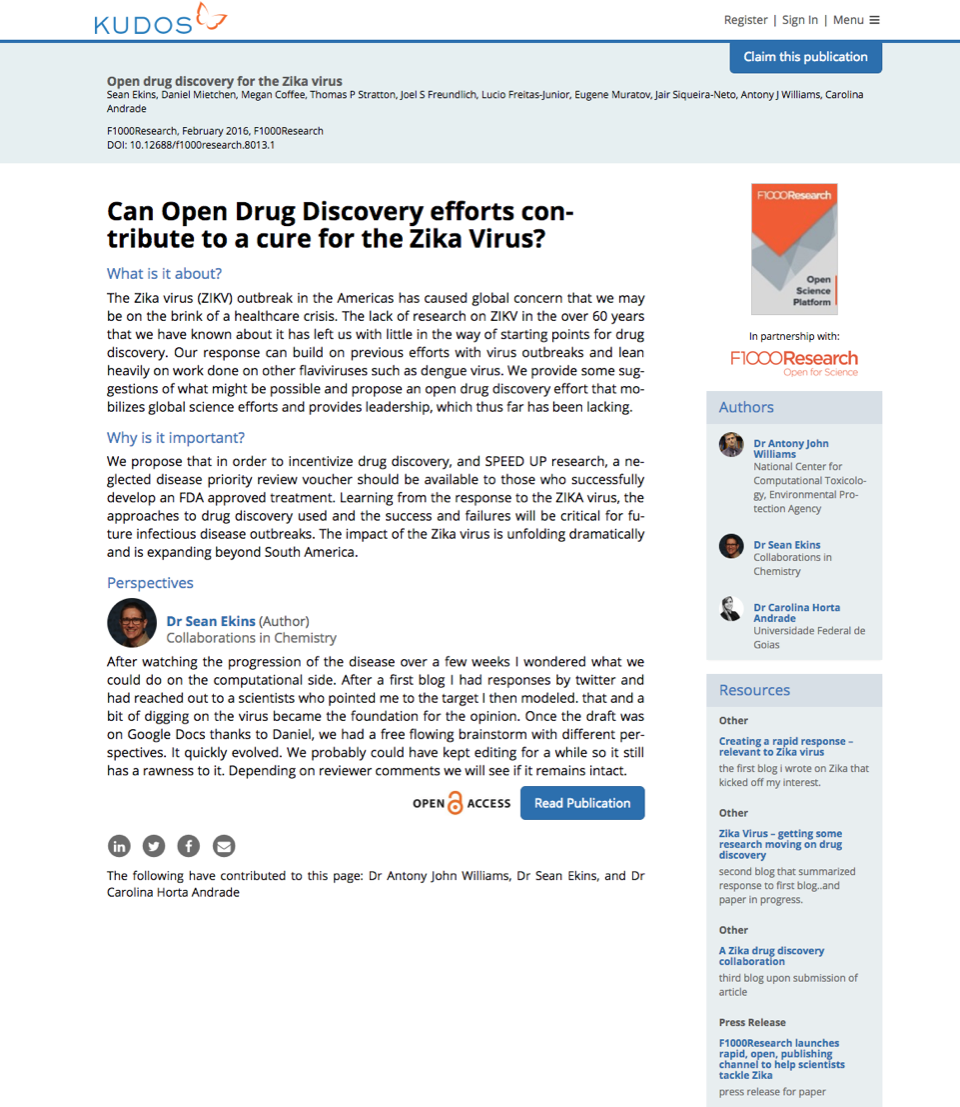
An example of a Kudos publication page showing the plain language summary
How is Crossref metadata used in Kudos?
Since our launch, Crossref has been our metadata foundation. When we receive notification from our publishing partners that an article, book or book chapter has been published, we query using the Crossref REST API to retrieve the metadata for that publication. That data allows us to populate the Kudos publication page.
We also integrate earlier in the researcher workflow, interfacing with all of the major Manuscript Submission Systems to support authors who want to build impact from the point of submission.
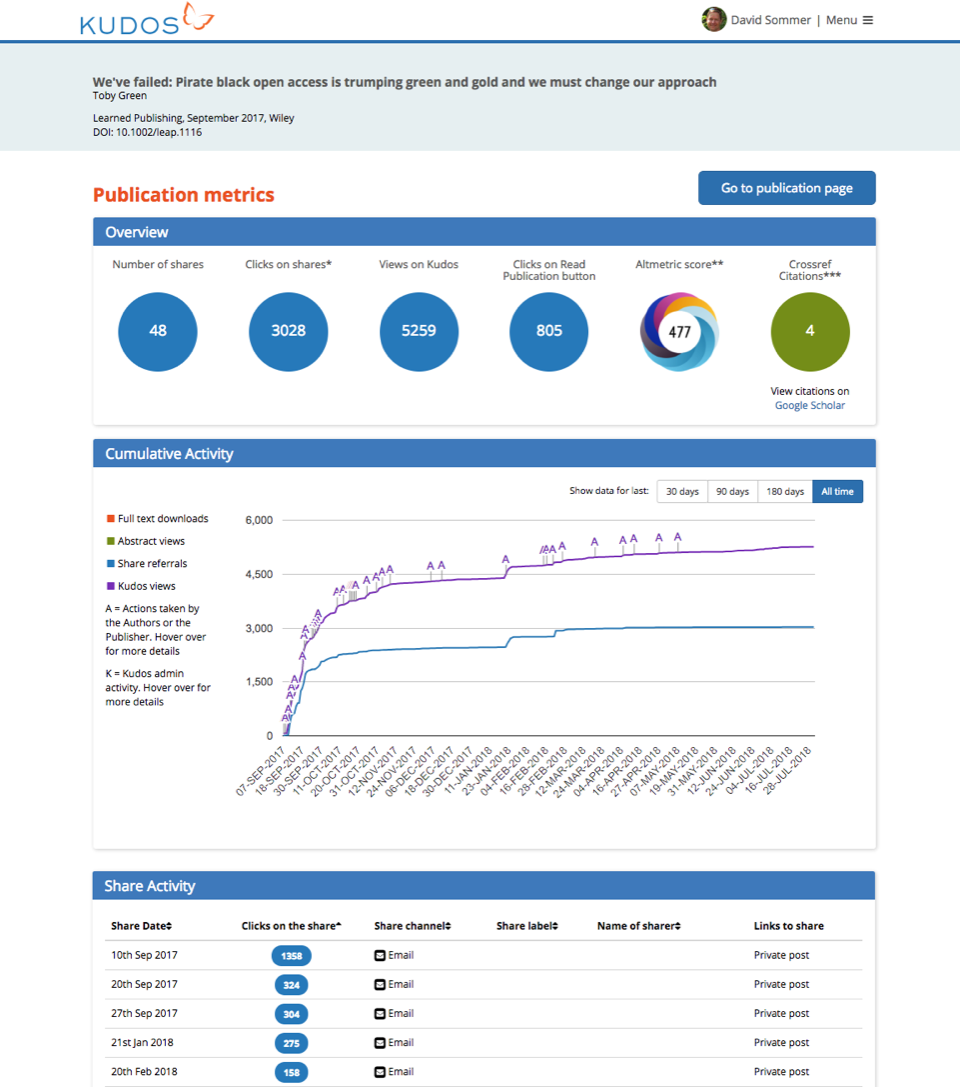
More recently, we started using the Crossref REST API to retrieve citation counts for a DOI. This enables us to include the number of times content is cited as part of the ‘basket of metrics’ we provide to our researchers. They can then understand the performance of their publications in context, and see the correlation between actions and results.
A Kudos metrics page, showing the basket of metrics and the correlation between actions and results
What are the future plans for Kudos?
We have exciting plans for the future! We are developing Kudos for Research Groups to support the planning, managing, measuring and reporting of dissemination activities for research groups, labs and departments. We are adding a range of new features and dissemination channels to support this, and to help researchers to better understand how their research is being used, and by whom.
What else would Kudos like to see in Crossref metadata?
We have always found Crossref to be very responsive and open to new ideas, so we look forward to continuing to work together. We are keen to see an industry standard article-level subject classification system developed, and it would seem that Crossref is the natural home for this.
We are also continuing to monitor Crossref Event Data which has the potential to provide a rich source of events that could be used to help demonstrate dissemination and impact.
Finally, we are pleased to see the work Crossref are doing to help improve the quality of the metadata and supporting publishers in auditing their data. If we could have anything we wanted, our dream would be to prevent “funny characters” in DOIs that cause us all kinds of escape character headaches!
Thank you David. If you would like to contribute a case study on the uses of Crossref Metadata APIs please contact the Community team.