Retractions and corrections from Retraction Watch are now available in Crossref’s REST API. Back in September 2023, we announced the acquisition of the Retraction Watch database with an ongoing shared service. Since then, they have sent us regular updates, which are publicly available as a csv file. Our aim has always been to better integrate these retractions with our existing metadata, and today we’ve met that goal.
This is the first time we have supplemented our metadata with a third-party data source.
As a provider of foundational open scholarly infrastructure, Crossref is an adopter of the Principles of Open Scholarly Infrastructure (POSI). In December 2024 we posted our updated POSI self-assessment. POSI provides an invaluable framework for transparency, accountability, susatinability and community alignment. There are 21 other POSI adopters.
Together, we are now undertaking a public consultation on proposed revisions for a version 2.0 release of the principles, which would update the current version 1.
https://0-doi-org.libus.csd.mu.edu/10.13003/axeer1ee
In our previous entry, we explained that thorough evaluation is key to understanding a matching strategy’s performance. While evaluation is what allows us to assess the correctness of matching, choosing the best matching strategy is, unfortunately, not as simple as selecting the one that yields the best matches. Instead, these decisions usually depend on weighing multiple factors based on your particular circumstances. This is true not only for metadata matching, but for many technical choices that require navigating trade-offs.
Looking back over 2024, we wanted to reflect on where we are in meeting our goals, and report on the progress and plans that affect you - our community of 21,000 organisational members as well as the vast number of research initiatives and scientific bodies that rely on Crossref metadata.
In this post, we will give an update on our roadmap, including what is completed, underway, and up next, and a bit about what’s paused and why.
ROR IDs and Affiliations of authors can now be tracked in Participation Reports! Check your own Participation Report to see how many of your publications have author affiliations and ROR IDs in Crossref metadata. If you deposit metadata via XML, see our guide on Affiliations and ROR for instructions on how to include affiliations and ROR IDs in your metadata.
Crossref encourages our members to include ROR IDs in metadata in order to help make research organization information clear and consistent as it is shared between systems. ROR IDs are essential to realize a rich and complete Research Nexus because they enable connections between research outputs and the organizations that support researchers.
“At Scholastica, we care about taking steps to enrich metadata – like adding ROR IDs, for example, on behalf of our customers, so they don’t have to worry about the technical aspects of metadata collection or creation and can instead focus on maximizing the discovery benefits.” – Cory Schires, Co-founder and Chief Technology Officer, Scholastica
“If we’re talking about misconduct, then you might need to be able to contact the institution that the author is from. On an individual manuscript, it doesn’t matter if there’s no identifier – an address will do. But if you find some signal that is on manuscripts at scale, and you’ve got thousands of them, well, you need an identifier. You can’t go through them and try and search for every single one of those institutions.” – Adam Day, CEO, Clear Skies Ltd.
ROR IDs are specifically designed to be implemented in any system that captures institutional affiliations and to enable a richer networked research infrastructure. ROR IDs are interoperable with other organization identifiers, including GRID (which provided the seed data that ROR launched with), the Open Funder Registry, ISNI, and Wikidata. ROR data is available under a CC0 Public Domain waiver and can be accessed at no cost via a public API and a data dump.
ROR is operated as a joint initiative by Crossref, DataCite, and the California Digital Library, and was launched with seed data from GRID in collaboration with Digital Science. These organizations have invested resources into building an open registry of research organization identifiers that can be embedded in scholarly infrastructure to effectively link research to organizations. ROR is not a membership organization (or an organization at all!) and charges no fees for use of the registry or the API. Read more about ROR’s sustainability model.
Why ROR IDs are an important element of Crossref metadata
For a long time, Crossref only collected affiliation metadata as free-text strings, which made for ambiguity and incomplete data. An author affiliated with the University of California at Berkeley might give the name of the university in any of several common ways:
University of California, Berkeley
University of California at Berkeley
University of California Berkeley
UC Berkeley
Berkeley
And likely more …
While it isn’t too difficult for a human to guess that “UC Berkeley,” “University of California, Berkeley,” and “University of California at Berkeley” are all referring to the same university, a machine interpreting this information wouldn’t necessarily make the same inference. If you are trying to easily find all of the publications associated with UC Berkeley, you would need to run and reconcile multiple searches at best, or, at worst, miss some data completely.
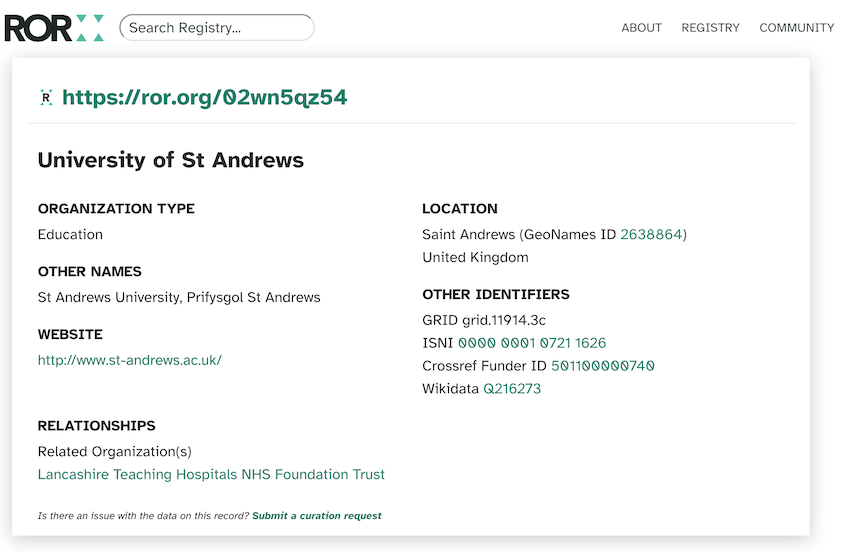
This is where an organization identifier comes in: a single, unambiguous, standardized identifier that will always stay the same. For UC Berkeley, that would be https://ror.org/01an7q238.
In 2019, Crossref members indicated that the ability to associate research outputs with organizations in a clean and consistent fashion was one of their most desired improvements to Crossref metadata. In January of 2022, therefore, Crossref added support for ROR IDs in its metadata schema and APIs. Since then, more and more Crossref members have been including ROR IDs in DOI metadata.
Publishers and service providers can implement ROR in their systems so that submitting authors and co-authors can easily choose their affiliation from a ROR-powered list instead of typing in free text. Authors themselves do not have to provide a ROR ID or even know that a ROR ID is being collected. This affiliation information can then be sent to Crossref alongside other publication information.
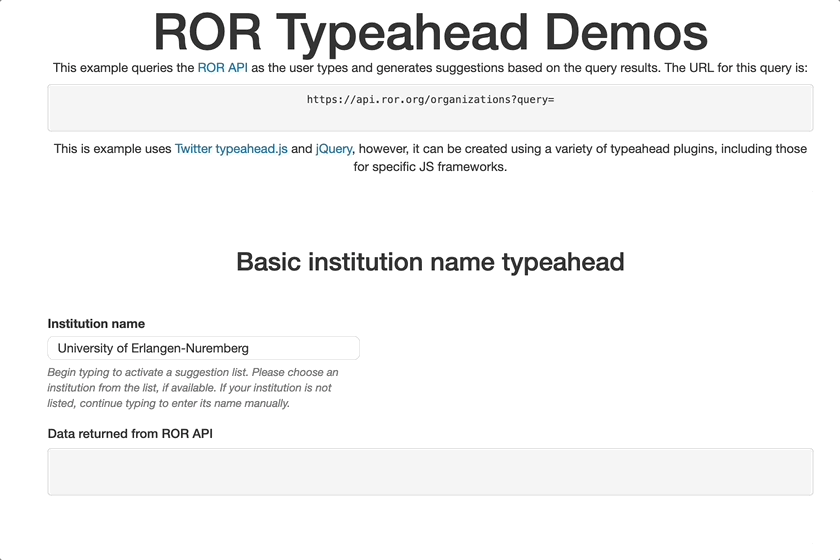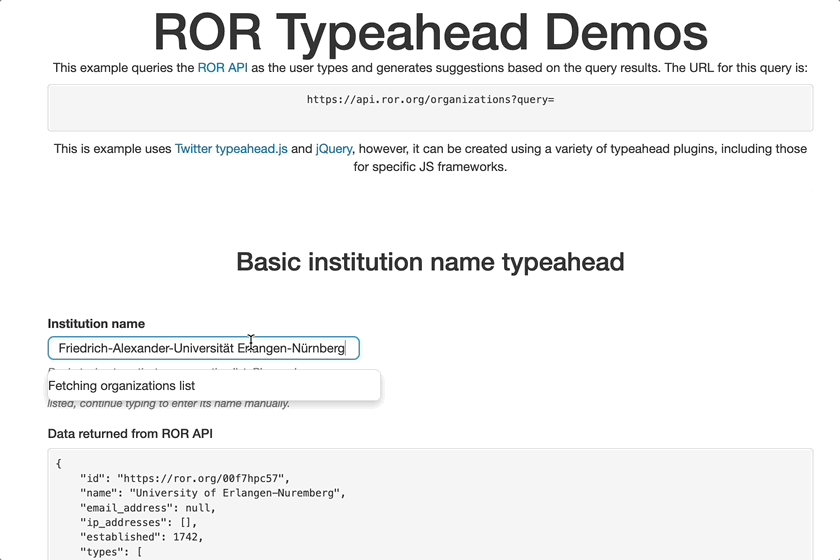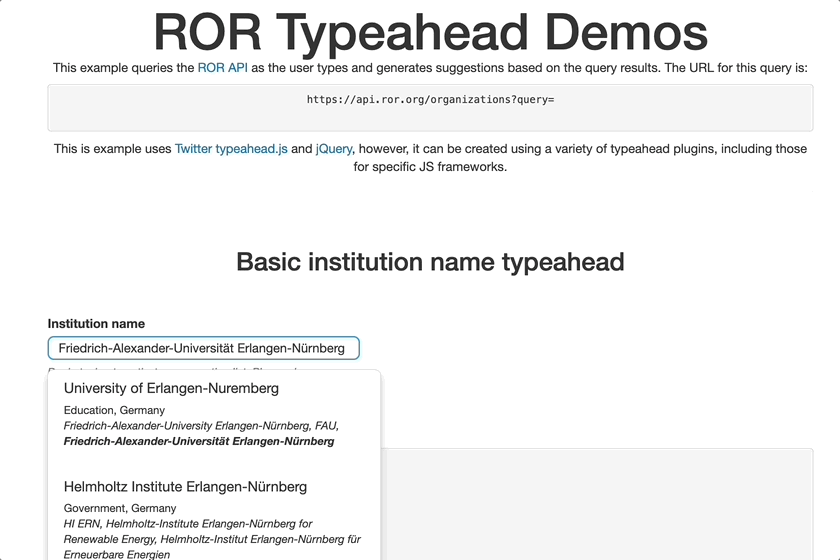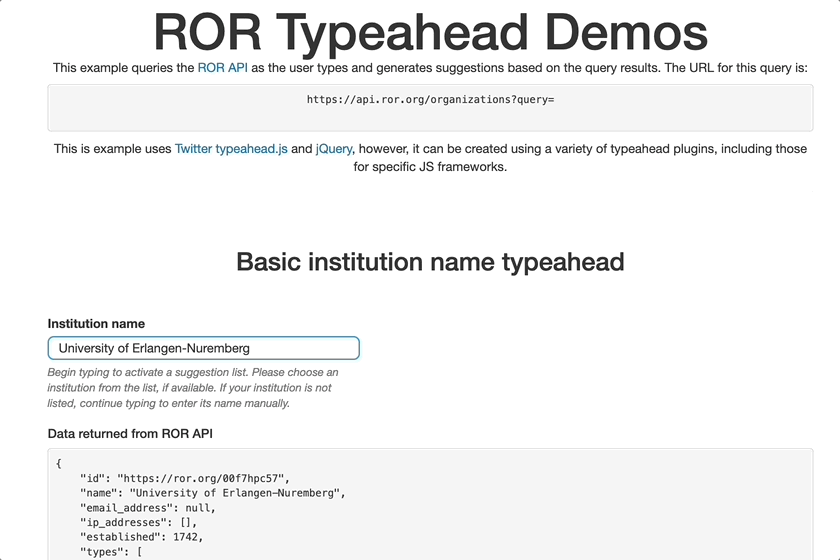
Demo of collecting ROR IDs in a typeahead field
If the submission system you use does not yet support ROR, or if you don’t use a submission system, you’ll still be able to provide ROR IDs in your Crossref metadata. ROR IDs can be added to JATS XML, and Crossref helper tools will start to support the deposit of ROR IDs. There’s also an OpenRefine reconciler that can map your internal identifiers to ROR identifiers.
ROR IDs for affiliations stand to transform the usability of Crossref metadata. While it’s crucial to have IDs for affiliations, it’s equally important that the affiliation data can be easily used. The ROR dataset is CC0, so ROR IDs and associated affiliation data can be freely and openly used and reused without any restrictions.
The ROR IDs registered by members in their Crossref metadata are available via Crossref’s open APIs so that they can be detected, analyzed, and reused by anyone interested in linking research outputs to research organizations. Examples include
Institutions who want to monitor and measure their research output by the articles their researchers have published
Funders who want to be able to discover and track the research and researchers they have supported
Academic librarians who want to find all of the publications associated with their campus
Journals who want to know where authors are affiliated so they can determine eligibility for institutionally sponsored publishing agreements
The inclusion of ROR IDs in Crossref metadata will eventually help all these entities make all these connections much more easily.
Get ready to ROR 🦁!
ROR is already working with publishers, funders and service providers who are integrating ROR in their systems, mapping their affiliation data to ROR IDs, and/or including ROR IDs in publication metadata. Libraries and institutional repositories are also beginning to build ROR into their systems and to send ROR IDs to Crossref in their metadata. See the growing list of active and in-progress ROR integrations for more stakeholders who are supporting ROR.
If you deposit metadata with Crossref via XML, see our guide on Affiliations and ROR for instructions on how to include author affiliations and ROR IDs.
For further information on how ROR IDs are supported in the Crossref metadata, you can take a look at this .xsd file (under the ‘institution’ element) or in this journal article example XML. ROR also has some great help documentation for publishers and anyone else working with the ROR Registry.