We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
When someone links their data online, or mentions research on a social media site, we capture that event and make it available for anyone to use in their own way. We provide the unprocessed data—you decide how to use it.
Before the expansion of the Internet, most discussion about scholarly content stayed within scholarly content, with articles citing each other. With the growth of online platforms for discussion, publication and social media, we have seen discussions extend into new, non-traditional venues.
Crossref Event Data captures this activity and acts as a hub for the storage and distribution of this data. An event may be a citation in a dataset or patent, a mention in a news article, Wikipedia page or on a blog, or discussion and comment on social media.
How Event Data works
Event Data monitors a range of sources, chosen for their importance in scholarly discussion. We make events available via an API for users to access and interpret. Our aim is to provide context to published works and connect diverse parts of the dialogue around research. Learn more about the sources from which we capture events.
The Event Data API provides raw data about events alongside context: how and where each event was collected. Users can process this data to suit their requirements.
What is Event Data for?
Event Data can be used for a number of different purposes:
Authors can find out where their work has been reused and commented on.
Readers can access more context around published research, including links to supporting documents and commentary that aren’t in a journal article.
Publishers and funders can assess the impact of published research beyond citations.
Service providers can enrich, analyze, interpret and report via their own tools
Data intelligence and analysis organisations can access a broad range of sources with commentary relevant to research articles.
Anyone can contribute to Event Data by mentioning the DOI or URL of a Crossref-registered work in one of the monitored sources. We also welcome third parties who wish to send events or contribute to code that covers new sources. Learn more about contributing to or using Crossref Event Data.
Agreement and fees for Event Data
Event Data is a public API, giving access to raw data, and there are no fees. In the future we will introduce a service-based offering with additional features and benefits. Learn more about the Event Data terms.
What is an event?
In the broadest sense, an event is any time someone refers to a research article with a registered DOI anywhere online. Ideally we would capture all events, but there are limitations:
We can’t monitor the entire Internet, and instead check sites that are most likely to discuss academic content. There are still venues that could be relevant and that we do not cover yet.
Users online refer to academic content in different ways, sometimes using the DOI but more often using the URL or just the article name. We try to decode mentions of DOIs or a publisher website to get a match to an article but it isn’t always possible. This means we may miss mentions of an article even from sources we are tracking.
At present we are not able to track events where no link is included and only the title or other part of the metadata is mentioned.
For Crossref Event Data, an event consists of three parts:
A subject: where was the research mentioned? (such as Wikipedia)
An object: which research was mentioned? (a Crossref or DataCite DOI)
A relationship: how was the research mentioned? (such as cites or discusses)
We determine the relationship from the source of the event, it is an indication of how the subject and object are linked based on broad categories.
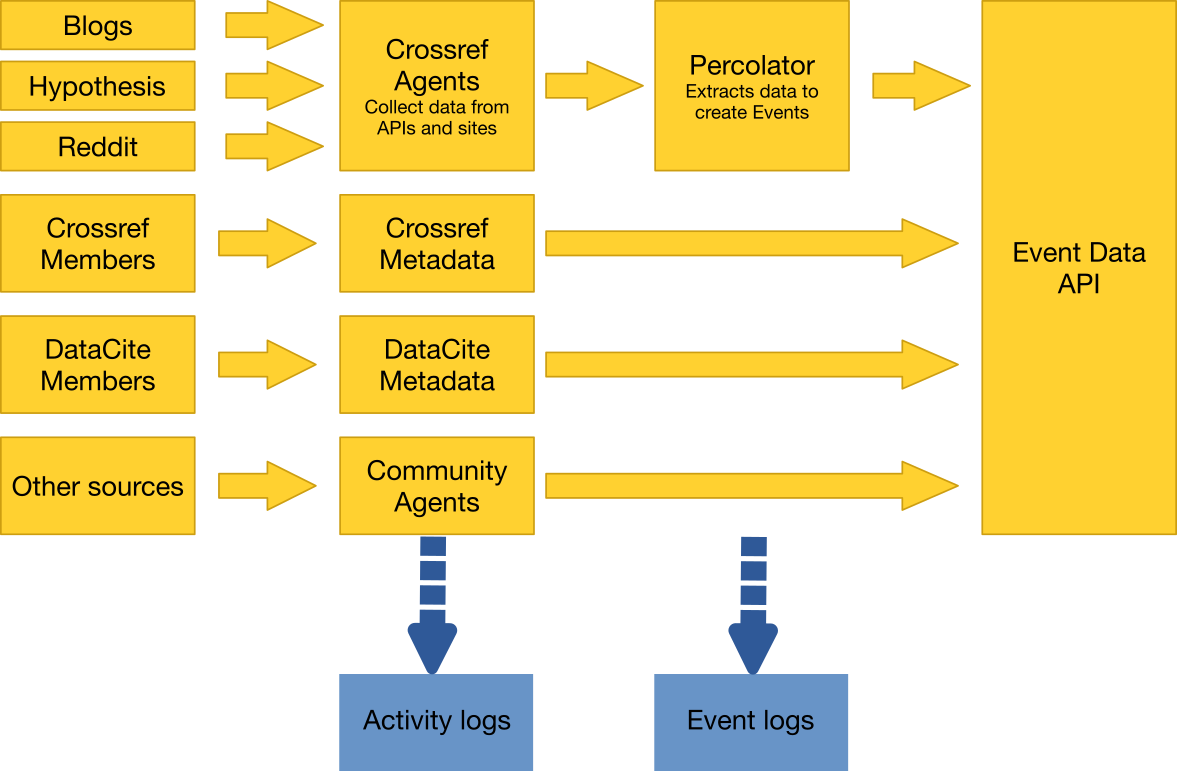
Software called agents collect events from various data sources. Most agents are written and operated by Crossref with some code written by our partners. Possible events are passed to the percolator software, which tries to match the event with an object DOI. This process is fully automated.
We perform periodic automated checks to the integrity of the data and update event types. Deduplication is also part of the process performed by the percolator.
To provide transparency, we keep an evidence record about how we matched the object to the subject. Learn more about transparency in Event Data, including links to the open source code and data.
The following agents currently collect data:
Agent/Data source
Event type
Crossref metadata
Relationships, references, and links to DataCite registered content
DataCite metadata
Links to Crossref registered content
Faculty Opinions
Recommendations of research publications
Hypothes.is
Annotations in Hypothes.is
Newsfeed
Discussed in blogs and media
Reddit
Discussed on Reddit
Reddit Links
Discussed on sites linked to in subreddits
Stack Exchange Network
Discussed on StackExchange sites
Wikipedia
References on Wikipedia pages
Wordpress.com
Discussed on Wordpress.com sites
We are planning to increase the number of agents and sources and welcome contact from anyone who can contribute. Patent Event Data was historically collected from The Lens. Events from Twitter were collected until February 2023, note that all Twitter events have been removed from search results in accordance with our contract with Twitter; see the Community Forum for more information.
What Event Data is not
By providing Event Data, Crossref provides an open, transparent information source for the scholarly community and beyond. It is important to understand, however, that it may not be suitable for all potential users. Here are some of the limitations:
It is not a service that provides metrics, collated reports, or offers data analysis.
Crossref does not build applications or website plugins for Event Data, for example for displaying results on publisher websites. We do, however, welcome third parties who wish to develop such platforms.
Event Data collection is fully automated and therefore may contain errors or be incomplete, we cannot provide any guarantees in this regard and users must assess the quality of the data required for their particular use case. There may also be delays between an event occurring and it appearing in Event Data.
Events might be missed due to the limitations of the collection algorithms we use. There is also a small possibility that we link an event to the wrong object.
Event Data does not cover every source of academic discussion. In some cases this is because there is no public access to the data; in others it is because we have not had the capacity to build an agent.
While we hope the data is useful for many purposes, we encourage users to be responsible and exercise caution when making use of Event Data.
Page owner: Martyn Rittman | Last updated 2020-October-06