We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
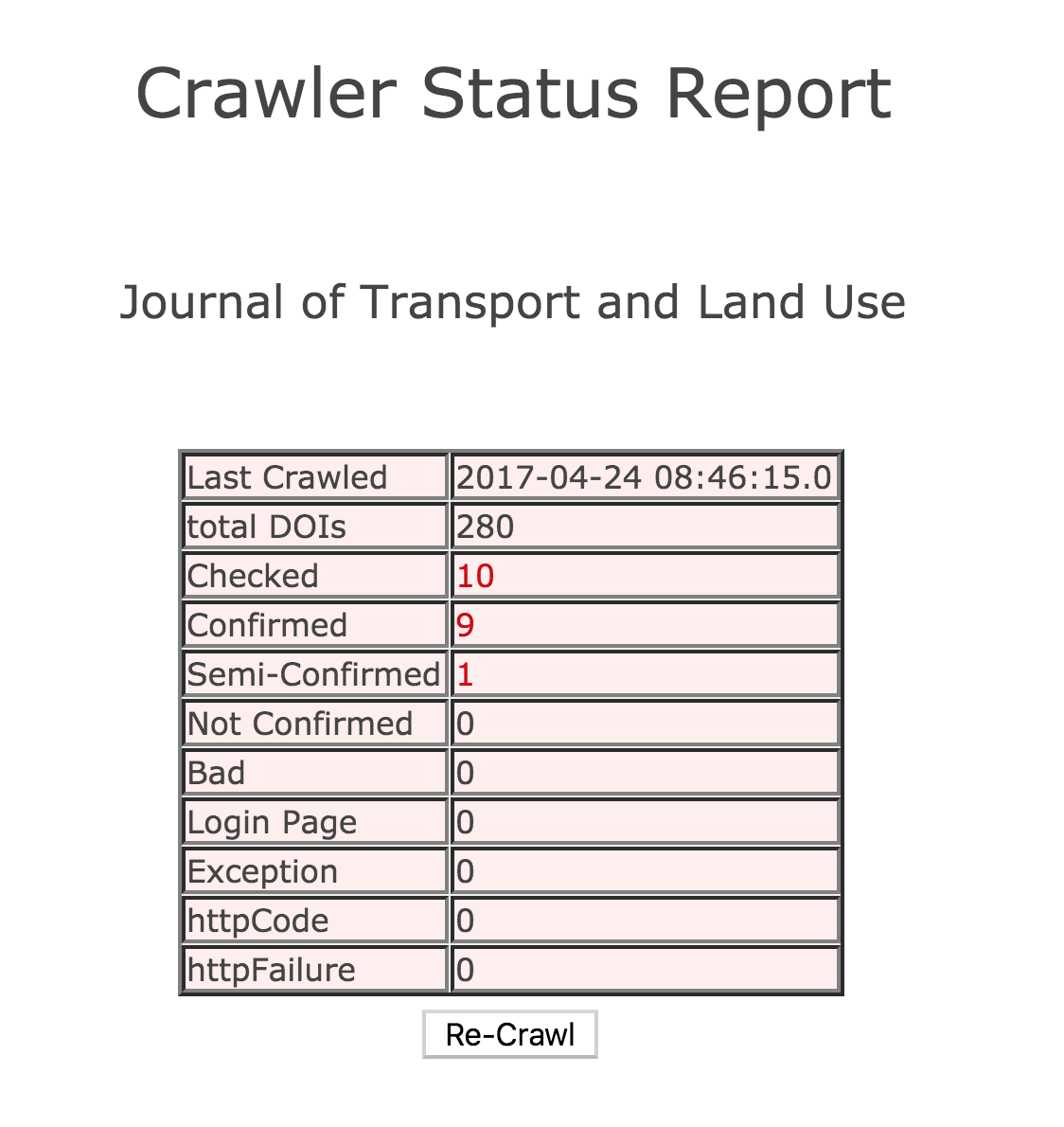
We test a broad sample of DOIs to ensure resolution. For each journal crawled, a sample of DOIs that equals 5% of the total DOIs for the journal up to a maximum of 50 DOIs is selected. The selected DOIs span prefixes and issues.
The results are recorded in crawler reports, which you can access from the depositor report expanded view (access the depositor reports by type at the links below).