We’ve just released an update to our participation report, which provides a view for our members into how they are each working towards best practices in open metadata. Prompted by some of the signatories and organizers of the Barcelona Declaration, which Crossref supports, and with the help of our friends at CWTS Leiden, we have fast-tracked the work to include an updated set of metadata best practices in participation reports for our members.
It’s been a while, here’s a metadata update and request for feedback In Spring 2023 we sent out a survey to our community with a goal of assessing what our priorities for metadata development should be - what projects are our community ready to support? Where is the greatest need? What are the roadblocks?
The intention was to help prioritize our metadata development work. There’s a lot we want to do, a lot our community needs from us, but we really want to make sure we’re focusing on the projects that will have the most immediate impact for now.
In the first half of this year we’ve been talking to our community about post-publication changes and Crossmark. When a piece of research is published it isn’t the end of the journey—it is read, reused, and sometimes modified. That’s why we run Crossmark, as a way to provide notifications of important changes to research made after publication. Readers can see if the research they are looking at has updates by clicking the Crossmark logo.
We’re happy to note that this month, we are marking five years since Crossref launched its Grant Linking System. The Grant Linking System (GLS) started life as a joint community effort to create ‘grant identifiers’ and support the needs of funders in the scholarly communications infrastructure.
The system includes a funder-designed metadata schema and a unique link for each award which enables connections with millions of research outputs, better reporting on the research and outcomes of funding, and a contribution to open science infrastructure.
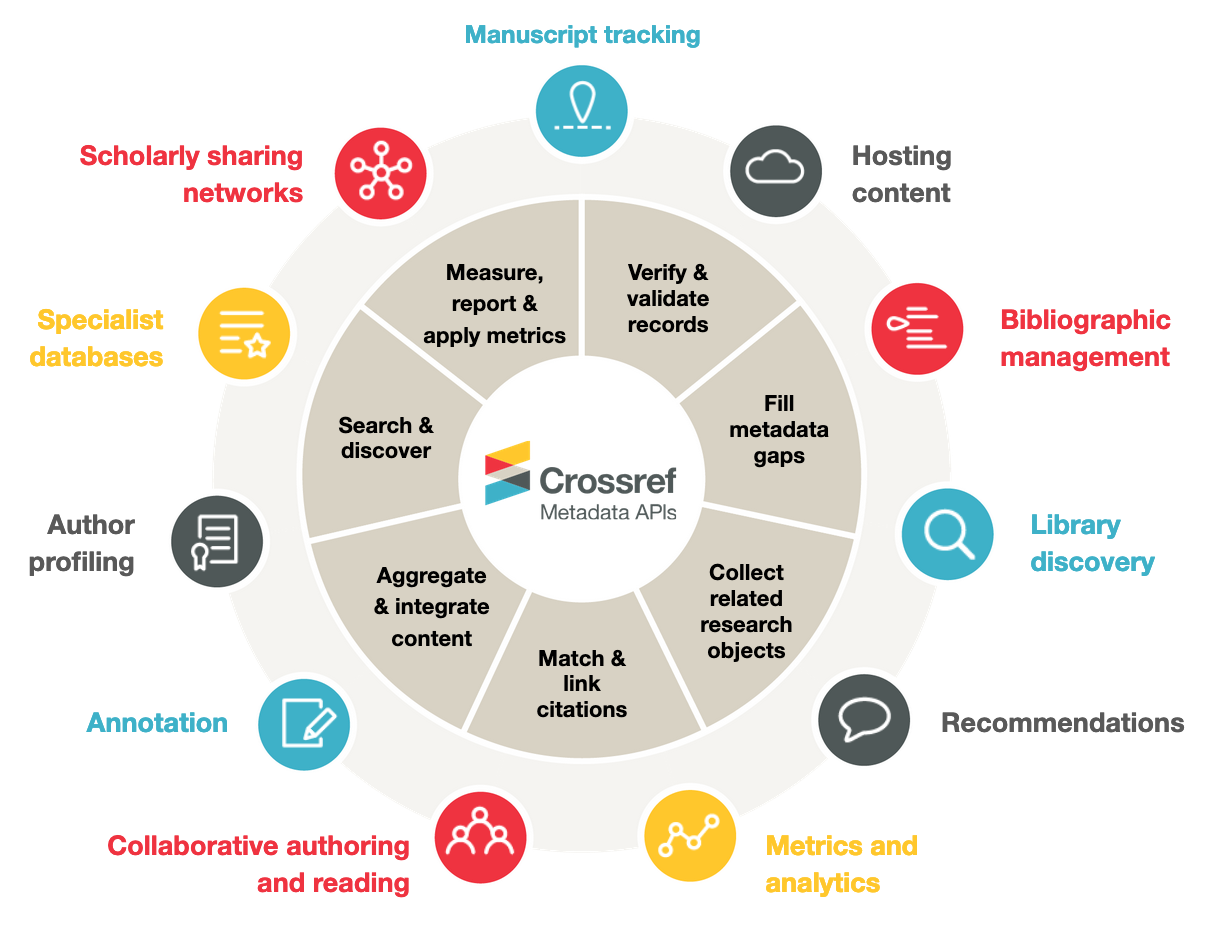
Some of the typical users (outer) and uses (inner) of Crossref metadata
People using Crossref metadata need it for all sorts of reasons including metaresearch (researchers studying research itself such as through bibliometric analyses), publishing trends (such as finding works from an individual author or reviewer), or incorporation into specific databases (such as for discovery and search or in subject-specific repositories), and many more detailed use cases.
All Crossref metadata is open and available for reuse without restriction. Our 160,104,382 records include information about research objects like articles, grants and awards, preprints, conference papers, book chapters, datasets, and more. The information covers elements like titles, contributors, descriptions, dates, references, connecting identifiers such as Crossref DOIs, ROR IDs and ORCID iDs, together with all sorts of metadata that helps to determine provenance, trust, and reusability—such as funding, clinical trial, and license information.
Anyone can retrieve and use 160,104,382 records without restriction. So there are no fees to use the metadata but if you really rely on it then you might like to sign up for Metadata Plus which offers greater predictability, higher rate limits, monthly data dumps in XML and JSON, and access to dedicated support from our team.
Options for retrieving metadata
All Crossref metadata is completely open and available to all. Whatever your experience with metadata, there are several tools, techniques, and support guides to help—whether you’re just beginning, exploring occasionally, or need an ongoing reliable integration.
BEGINNING?
You’ve heard Crossref metadata might be useful and want to know where to start.
You rely on Crossref metadata and need to incorporate it into your product at scale.
You might want to jump straight to subscribing to Metadata Plus, which is our premium service for the REST API that comes with monthly data dumps in JSON and XML, higher rate limits, and fast support. But we always recommend that you try out the public version first to make sure it will work for your product. If you’re looking for a single DOI record in multiple formats (e.g. RDF, BibTex, CSL) you can use content negotiation.
Watch the animated introduction to metadata retrieval